Search (ada) and Query (gpt-3.5-turbo) Your Codebases Using OpenAI's Embeddings and ChatGPT
So the ChatCompletion API that openai has is so new that to use it you must build and install the openai-python repo from source. I was pretty sure ChatGPT wouldn't know about this yet and when asking at https://chat.openai.com/chat I found I was right:
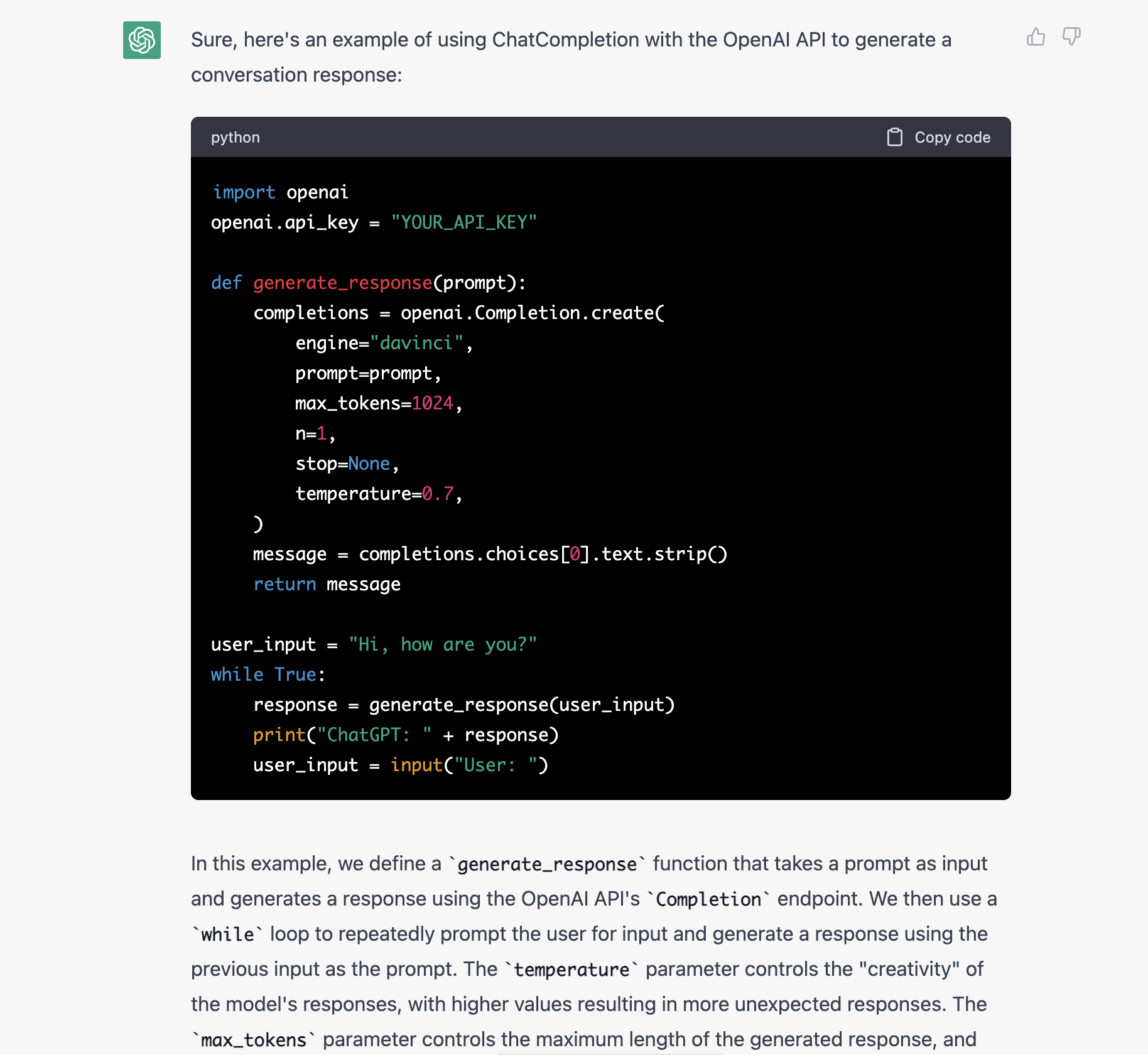
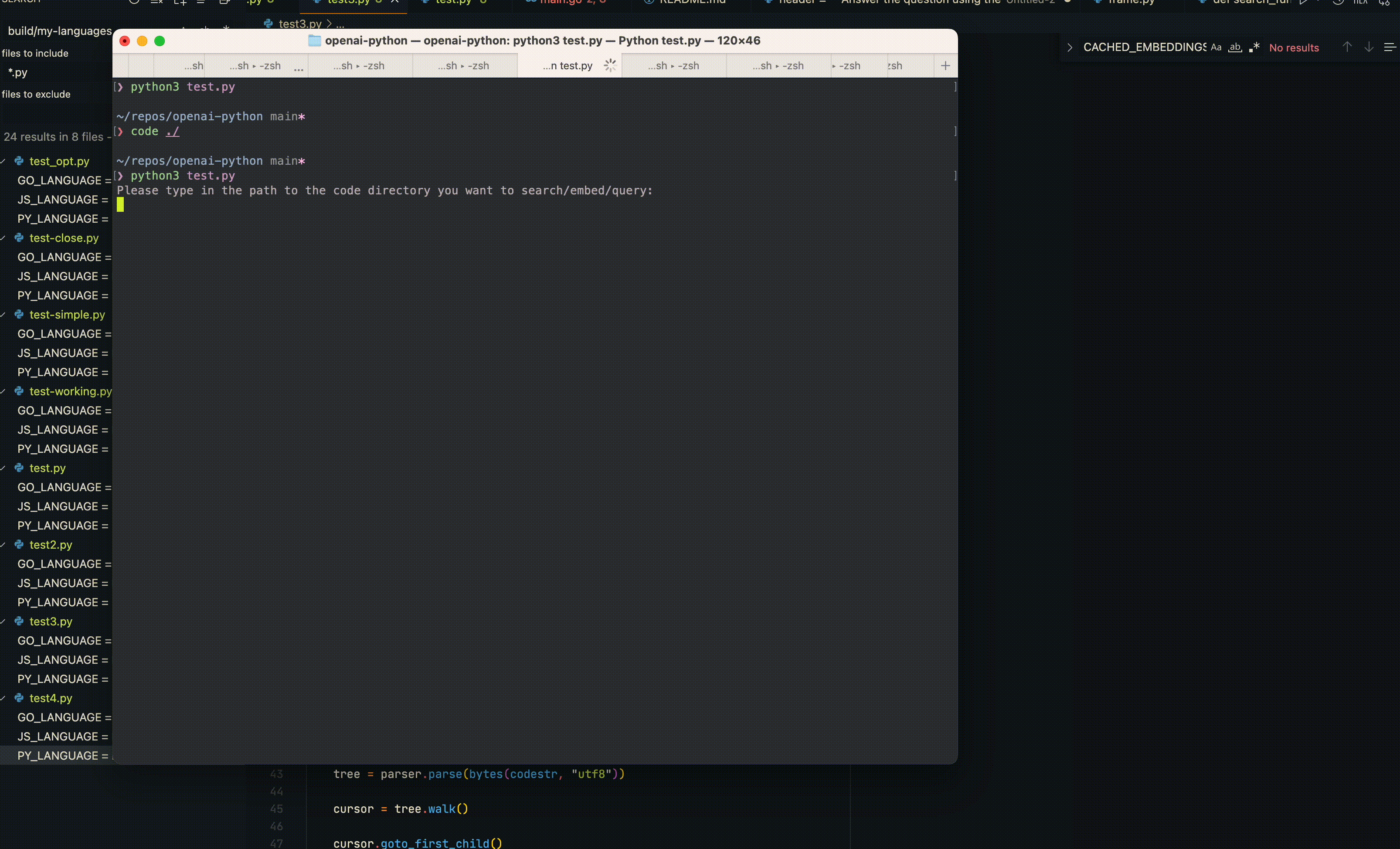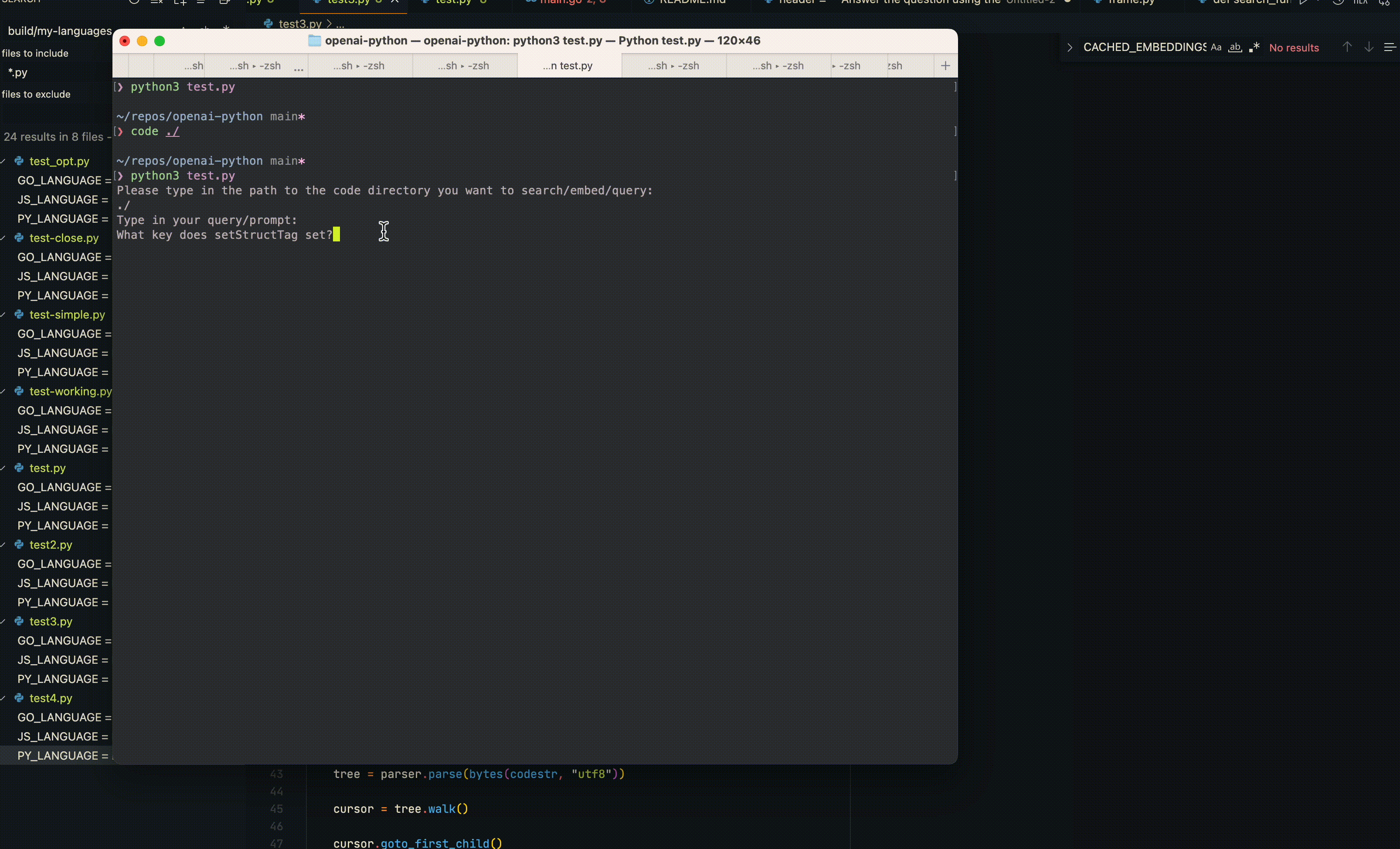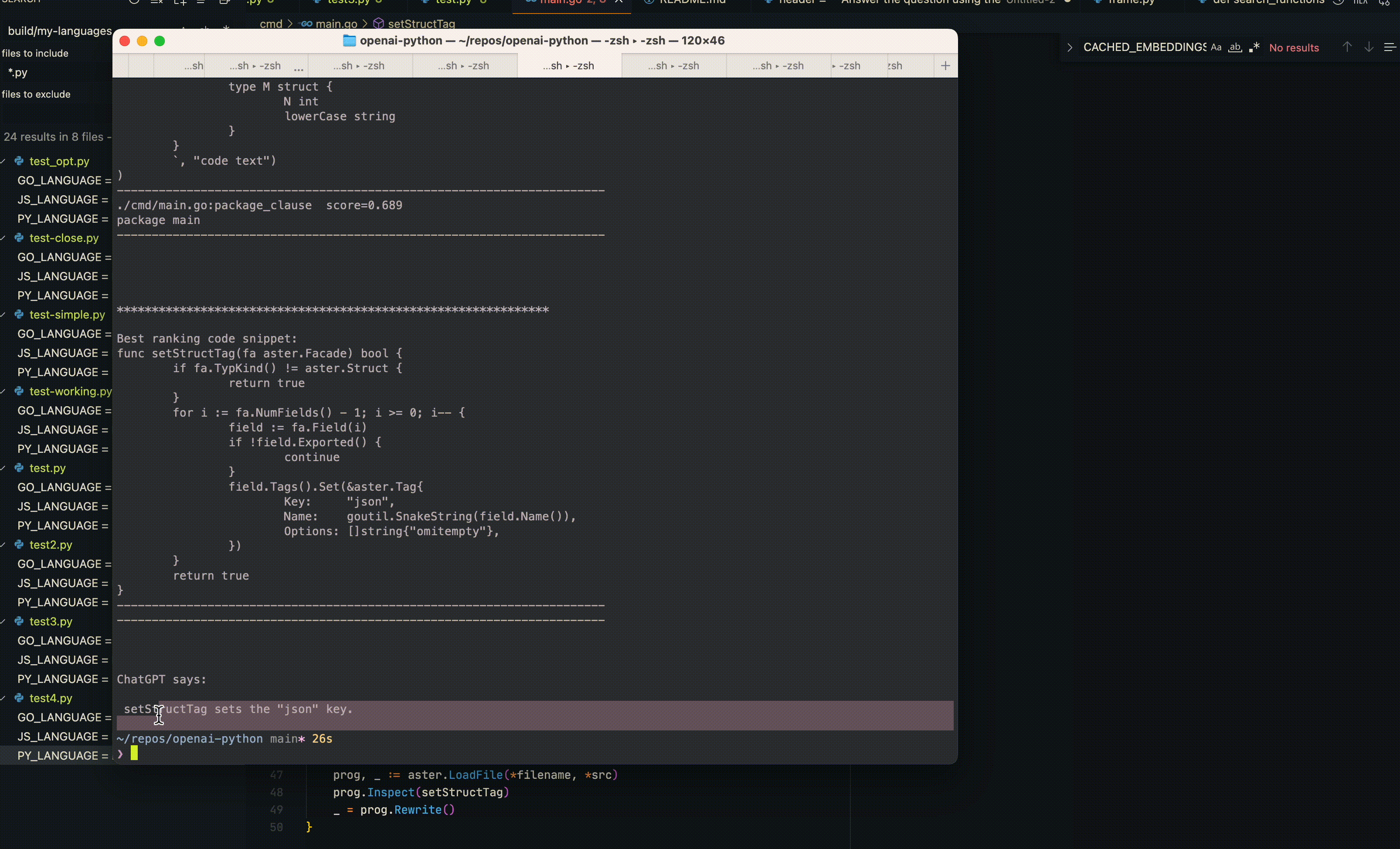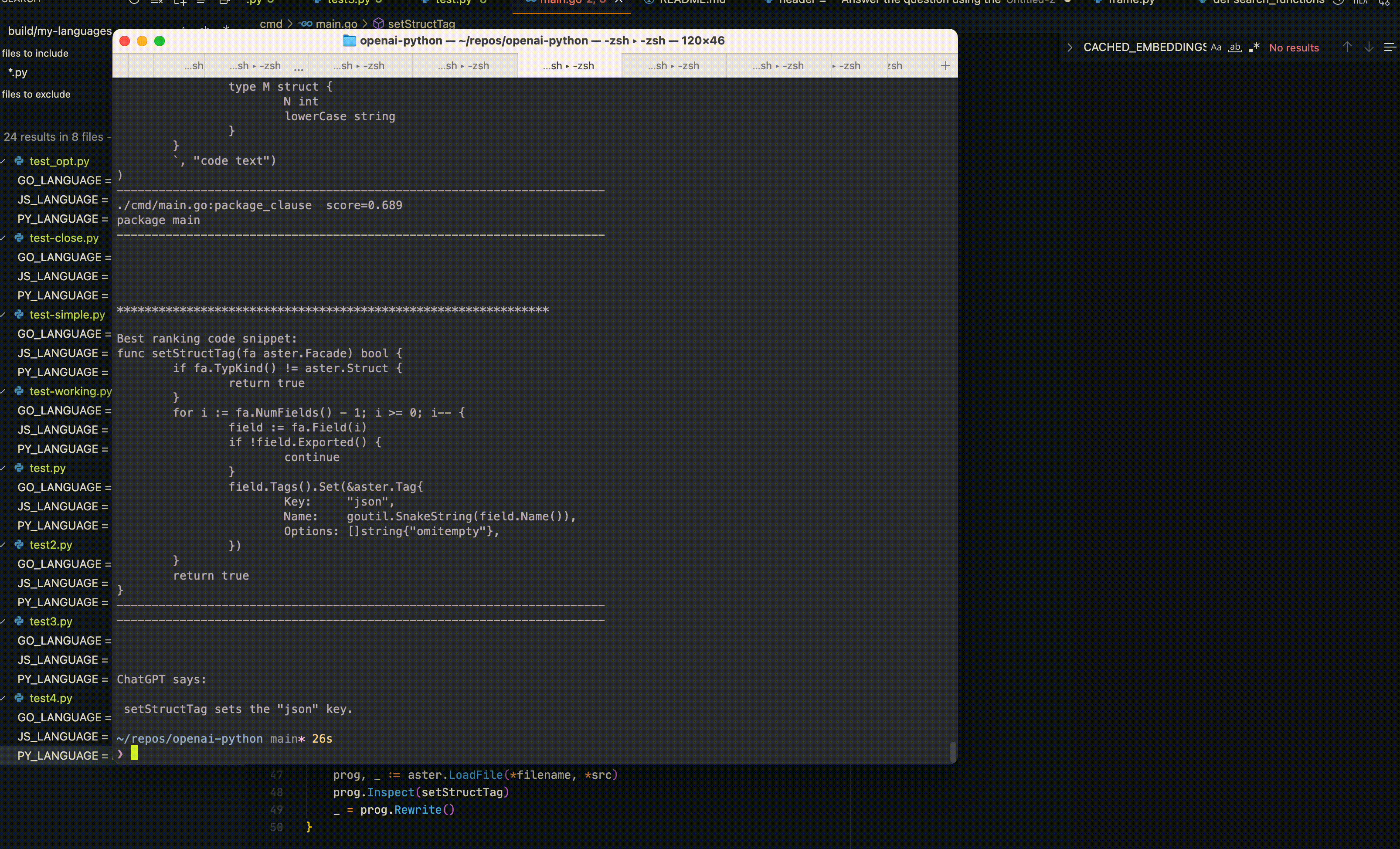
But when using the tool I have written here, searching through the openai-python codebase (creating embeddings for all python code in this repo and finding the best ones to include in the ChatCompletion/ChatGPT prompt) it works great:
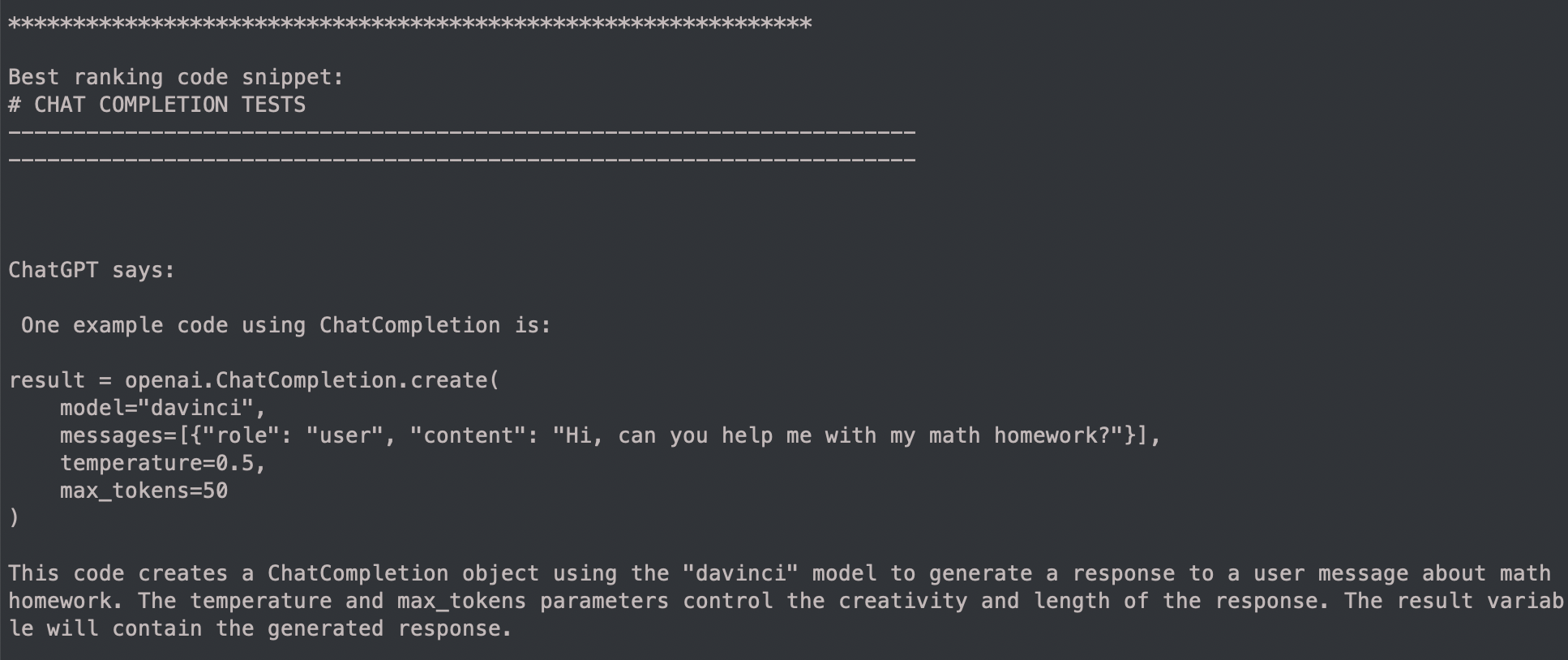
The repo is here.
I love ChatGPT. But I really wanted to see if it could be used to search through and provide useful answers about the codebases I work with day to day. This script is still pretty rough right now but I wanted to push it up in case anyone else has been trying to do this. I will clean this up when I get time.
Tree sitter is used to parse through whatever language and then it sends off parts of the AST as embeddings to OpenAI. Then the embeddings are searched to find the most similar ones to your query using text-embedding-ada-002 and finally the top related code that is found with text-embedding-ada-002 is then used in a prompt to ChatGPT (gpt-3.5-turbo).
I couldn't find any good working examples of this, especially with the language support that I have (tree-sitter will support any language that ChatGPT does).
Right now it is set to search just through GoLang code. But just change the
current_language
variable to whatever language you want to search/query.
There is a lot of code I am still refactoring and cleaning up. But it works great! So have fun.
- Combine embeddings of the same node_type that are adjacent to each other
- Use num_tokens_from_string to make sure my embeddings/query are the right size
I have included the build folder so you can skip the instructions from https://github.com/tree-sitter/py-tree-sitter
But you need to clone the following repos:
git clone https://github.com/tree-sitter/tree-sitter-go
git clone https://github.com/tree-sitter/tree-sitter-javascript
git clone https://github.com/tree-sitter/tree-sitter-python
Then run the following code in python:
from tree_sitter import Language, Parser
Language.build_library(
# Store the library in the `build` directory
'build/my-languages.so',
# Include one or more languages
[
'tree-sitter-go',
'tree-sitter-javascript',
'tree-sitter-python'
]
)
to rebuild your own or add new languages.
python3 -m pip install matplotlib
python3 -m pip install plotly
python3 -m pip install scipy
python3 -m pip install sklearn
python3 -m pip install pandas
python3 -m pip install tree_sitter
python3 -m pip install tiktoken
And you must install openai-python from the repo so you can use the new ChatCompletion API.
python3 searchandchat.py